[ 중복이 없는가 ]
문자열이 주어졌을 때 이 문자열에 같은 문자가 중복되어 등장하는지 확인하는 알고리즘
예시) hi ⇒ True, hello ⇒ False(l이 2개)
def isUniqueChars(string):
char_set = set()
for s in string:
if s in char_set: return False
else: char_set.add(s)
return True👀 set을 사용한 이유는 특정 원소를 검색하는 연산이 O(1)의 시간 복잡도를 가지기 때문입니다. dictionary도 검색 연산이 O(1)이지만 굳이 키 값을 넣을 필요는 없기 때문에 사용하지 set으로 사용했습니다.
[ 순열 확인 ]
문자열 두 개가 주어졌을 때 이 둘이 서로 순열 관계에 있는지 확인하는 알고리즘
예시) dog, god ⇒ True
⭐ 순열 : 서로 다른 n개의 원소에서 r개의 중복없이 순서에 상관있게 선택하는 혹은 나열하는 것
def isPermutation(string1, string2):
if len(string1) != len(string2): return False
dic1, dic2 = {}, {}
for s1, s2 in zip(string1, string2):
dic1.setdefault(s1, 0)
dic1[s1] += 1
dic2.setdefault(s2, 0)
dic2[s2] += 1
return dic1 == dic2👀 dictionary로 {"문자": 갯수}로 비교했습니다. set과 count를 이용하는 방법을 생각해보았지만 번거로울 것 같아서 dictionary로 코드를 구성했습니다. 사실 Counter를 사용하면 코드를 줄일 수 있습니다.(제일 좋아하는 방법)
from collections import Counter
def isPermutation_Counter(string1, string2):
if len(string1) != len(string2): return False
return Counter(string1) == Counter(string2)
[ URL화 ]
문자열에 들어 있는 모든 공백을 '%20'으로 바꾸는 알고리즘
예시) Hello World ⇒ Hello%20World
def replaceSpaces(url):
result = ""
for s in url:
result += "%20" if s == " " else s
return result👀 파이썬에서는 replace를 사용하면 쉽게 작업할 수 있습니다. replace 외에도 다른 방법을 생각해본다면 split과 join을 사용할 수도 있습니다.
def replaceSpaces_Replace(url):
return url.replace(" ", "%20")
def replaceSpaces_SplitJoin(url):
return '%20'.join(url.split(' '))
[ 회문 순열 ]
주어진 문자열이 회문의 순열인지 아닌지 확인하는 알고리즘. 꼭 사전에 등장하는 단어로 제한될 필요는 없습니다.
⭐ 회문 : 앞으로 읽으나 뒤로 읽으나 같은 문자열
예시) tact coa ⇒ True(taco cat, atco cta 등등)
def isPermutationOfPalindrome(string):
dic = {}
for s in string:
dic.setdefault(s, 0)
dic[s] += 1
return sum([v%2 for k, v in dic.items() if k != ' ']) < 2👀 문자열이 짝수이면 모든 문자는 짝수여야 하고 문자열이 홀수이면 한 개의 문자는 홀수이고 나머지는 짝수여야 합니다. 그리하여 문자열에서 문자 수를 센 다음 홀수인 문자가 2개 미만인지 확인합니다. 공백에 대한 것도 문자로 취급해야 하는지 의문이 들지만 공백의 경우 무시했습니다. 아래는 Counter 사용한 경우입니다.
from collections import Counter
def isPermutationOfPalindrome_Counter(string):
counter = Counter(string)
return sum([counter[k]%2 for k in counter if k != ' ']) < 2👀 일반적으로 문자열이 회문인지 확인하는 법은 간단합니다.
def isPalindrome(string):
return string == string[::-1]
[ 하나 빼기 ]
문자열 2개가 주어졌을 때, 문자열을 같게 만들기 위한 편집 횟수가 1회 이내인지 확인하는 알고리즘
⭐ 편집 방법 : 문자 삽입/삭제, 문자 교체
def oneEditAway(f, s):
if abs(len(f)-len(s)) > 1: return False
s1 = max(f, s, key=len)
s2 = s if s1 == f else f
idx1, idx2 = 0, 0
d = False
while idx1<len(s1) and idx2<len(s2):
if s1[idx1] != s2[idx2]:
if d: return False
d = True
if len(s1) == len(s2):
idx2 += 1
else:
idx2 += 1
idx1 += 1
return True👀 편집 방법의 경우 문자열의 길이와 관련이 있기 때문에 문자열이 긴 것과 짧은 것을 나눕니다. 그리고 편집 횟수가 1회 이내이기 때문에 d라는 boolean 변수를 사용하였습니다.
[ 문자열 압축 ]
반복되는 문자의 개수를 세는 방식의 기본적인 문자열 압축 알고리즘.
⭐ 만약 '압축된' 문자열의 길이가 기존 문자열의 길이보다 길다면 기존 문자열 반환
def compress(s):
cnt, pre, result = 0, s[0], ''
for i in s:
if pre == i:
cnt += 1
else:
result += pre+str(cnt)
if len(result) > len(s): return s
cnt = 1
pre = i
result += pre + str(cnt)
return s if len(result) > len(s) else result👀 pre라는 변수를 사용하여 이전 문자를 기록하고 cnt라는 변수를 사용하여 개수를 세었습니다. itertools의 groupby를 사용하면 코드는 간단해집니다. 하지만 "기존 문자열의 길이보다 길다면 기존 문자열 반환"이라는 조건 때문에 compress보다 시간적으로 빠르지는 않을 것 같습니다.
from itertools import groupby
def compress_Groupby(s):
result = ''.join([f'{_}{len(list(g))}' for _, g in groupby(s)])
return s if len(result) > len(s) else result
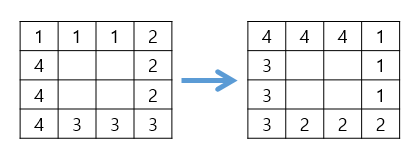
[ 행렬 회전 ]
이미지(N×N 행렬)를 90도 회전시키는 알고리즘
예시)
def rotate(matrix):
n = len(matrix)
for i in range(n//2):
first = i
last = n-1-i
for j in range(first, last):
offset = j - first
# 위쪽 임시 저장
top = matrix[first][j]
# 왼쪽 → 위쪽
matrix[first][j] = matrix[last-offset][first]
# 아래쪽 → 왼쪽
matrix[last-offset][first] = matrix[last][last-offset]
# 오른쪽 → 아래쪽
matrix[last][last-offset] = matrix[j][last]
# 위쪽 → 오른쪽
matrix[j][last] = top
return matrix👀 사실 python에서는 zip과 list[::-1]을 사용하면 90도 회전을 쉽게 할 수 있습니다.
def rotate(matrix):
return [list(i) for i in zip(*matrix[::-1])]
[ 0 행렬 ]
M×N 행렬의 한 원소가 0일 경우, 해당 원소가 속한 행과 열의 모든 원소를 0으로 설정하는 알고리즘
def setZeros(matrix):
dic = {"i": set(), "j": set()}
for i in range(len(matrix)):
for j in range(len(matrix[i])):
if matrix[i][j] == 0:
dic["i"].add(i)
dic["j"].add(j)
for i in dic["i"]:
for j in range(len(matrix[i])):
matrix[i][j] = 0
for j in dic["j"]:
for i in range(len(matrix)):
matrix[i][j] = 0
return matrix👀 풀긴 풀었는데 더 좋은 코드가 존재할 것 같습니다.
[ 문자열 회전 ]
s1과 s2이 주어졌을 때 s2가 s1을 회전시킨 결과인지 isSubstring(한 단어가 다른 문자열에 포함되어 있는지 판별) 메서드를 한 번만 호출해서 판별할 수 있는 알고리즘
예시) waterbottle, erbottlewat ⇒ True
def isRotation(s1, s2):
return isSubstring(s1+s1, s2)
def isSubstring(s3, s4):
return s4 in s3👀 s1 = ab일 때, s2 = ba입니다. s1s1 = abab이므로 s1s1에는 항상 s2가 포함되므로 isSubstring에 s1s1과 s2인자를 넘겨서 판별합니다. 위의 방법이 가장 간단한 방법이지만 아래와 같은 방법들도 있습니다.
def isRotation_For(s1, s2):
for i in range(len(s1)):
if s1[i:]+s1[:i] == s2:
return True
return False
from collections import deque
def isRotation_Deque(s1, s2):
tmp = deque(s1)
for i in range(len(s1)):
tmp.rotate(-1)
if ''.join(tmp) == s2:
return True
return False'프로그램 개발 > Python' 카테고리의 다른 글
| [코딩 인터뷰]자료구조 - 스택과 큐 문제(Python) (0) | 2022.12.06 |
|---|---|
| [코딩 인터뷰]자료구조 - 연결리스트 문제(Python) (1) | 2022.12.02 |
| [python] 정규표현식 예시 모음 (0) | 2022.11.29 |
| [python] 뫼비우스 함수 (0) | 2022.11.26 |
| [python] 소인수분해 (0) | 2022.11.25 |