[ 트리의 종류 ]
👀 트리
: 노드로 이루어진 자료구조입니다. 트리를 재귀적으로 설명하면 다음과 같습니다.
- 하나의 루트 노드를 갖습니다.
→ 사실 그래프 이론에서는 하나의 루트 노드를 가질 필요는 없습니다. - 루트 노드는 0개 이상의 자식 노드를 갖고 있습니다.
- 자식 노드 또한 0개 이상의 자식 노드를 갖고 있고 이는 반복적으로 정의됩니다.

⭐ Node
class Node{
public String name;
public Node[] childern;
}⭐ Tree
class Tree{
public Node root;
}
👀 이진트리(binary tree)
: 각 노드가 최대 2개의 자식을 갖는 트리

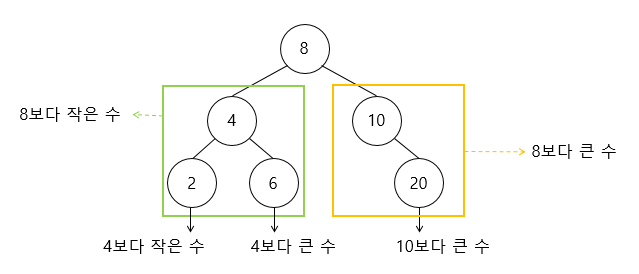
👀 이진 탐색 트리(binary search tree)
: 모든 노드가 다음과 같은 특정 순서를 따르는 속성이 있는 이진트리
"모든 왼쪽 자식들 ≤ n < 모든 오른쪽 자식들" 속성은 모든 노드 n에 대해서 반드시 참이어야 합니다.
👀 균형 트리
균형 트리의 일반적인 유형으로는 레드-블랙 트리와 AVL 트리가 있습니다.
⭐ 레드-블랙 트리와 AVL 트리는 추후에 좀 더 자세히 다룰 예정입니다.
⭐ 트리에서 균형을 잡는다는 것이 왼쪽과 오른쪽 부분 트리의 크기가 같게 하는 것을 의미하지 않습니다.
👀 완전 이진트리
: 트리의 모든 높이에서 노드가 꽉 차 있는 이진트리
⭐ 마지막 단계(level)는 꽉 차 있지 않아도 되지만 노드가 왼쪽에서 오른쪽으로 채워져야 합니다.

👀 전 이진트리
: 모든 노드의 자식이 없거나 정확히 2개 있는 트리

👀 포화 이진트리
: 전 이진트리이면서 완전 이진트리
⭐ 모든 말단 노드는 같은 높이에 있어야 하며 마지막 단계에서 노드의 개수가 최대가 되어야 합니다.

[ 이진트리 순회 ]
TreeNode 객체와 visit 함수 임의 정의(책에는 코드가 없어서 직접 만든 코드)▼
⭐ TreeNode : 이진 트리 순회기 때문에 child 배열 대신 left, right 노드로 설정했습니다.
class TreeNode{
private String name;
private Node left;
private Node right;
public boolean visited = false;
public Node(String name, Node left, Node right){
this.name = name;
this.left = left;
this.right = right;
}
}⭐ visit : 노드의 visited를 true로 변경하고 단순 출력하는 함수로 제작했습니다.
void visit(TreeNode node){
if(!node.visited){
node.visited = true;
System.out.println(node.name);
}
}
👀 중위 순회
: 왼쪽 가지, 현재 노드, 오른쪽 가지 순서로 노드를 '방문'하고 출력하는 방법
void inOrderTraversal(TreeNode node){
if(node != null){
inOrderTraversal(node.left);
visit(node);
inOrderTraversal(node.right);
}
}⭐ 이진 탐색 트리를 이 방식으로 순회한다면 오름차순으로 방문하게 됩니다.
👀 전위 순회
: 자식 노드보다 현재 노드를 먼저 방문하는 방법
void preOrderTraversal(TreeNode node){
if(node != null){
visit(node);
preOrderTraversal(node.left);
preOrderTraversal(node.right);
}
}⭐ 전위 순회에서 가장 먼저 방문하게 될 노드는 언제나 루트입니다.
👀 후위 순회
: 모든 자식 노드를 먼저 방문한 뒤 마지막에 현재 노드를 방문하는 방법
void postOrderTraversal(TreeNode node){
if(node != null){
postOrderTraversal(node.left);
postOrderTraversal(node.right);
visit(node);
}
}⭐ 후위 순회에서 가장 마지막에 방문하게 될 노드는 언제나 루트입니다.
[ 이진 힙(최소 힙과 최대 힙) ]
👀 최소 힙
: 완전 이진트리이며 각 노드의 원소가 자식들의 원소보다 작다는 특성이 있습니다. 즉 루트는 트리 전체에서 가장 작은 원소가 됩니다. 최소 힙에는 insert와 extract_min이라는 핵심 연산 2가지가 존재합니다.
⭐ 최대 힙은 최소 힙에서 원소가 내림차순으로 정렬되어있는 것과 같습니다.
👀 삽입(insert)
새로운 원소는 밑바닥 가장 오른쪽 위치로 삽입됩니다. 그다음에 새로 삽입된 원소가 제대로 된 자리를 찾을 때까지 부모 노드와 교환해 나갑니다.

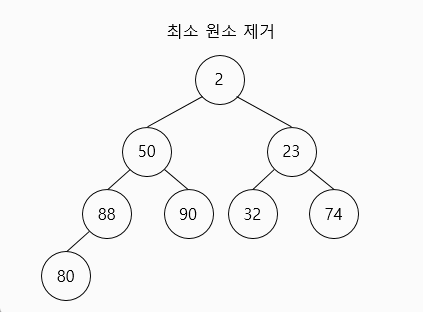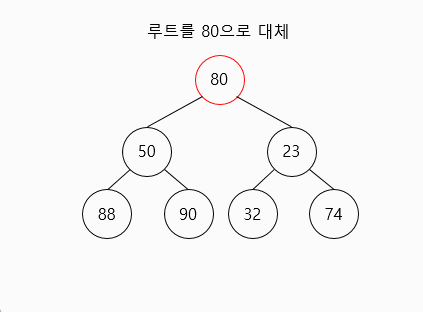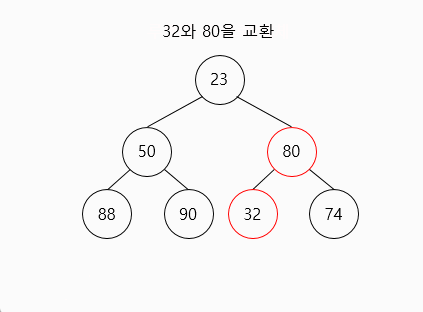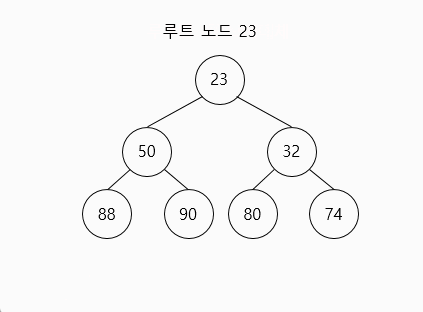
👀 최소 원소 뽑아내기(extract_min)
최소 원소는 언제나 루트입니다.
만약 최소 원소를 제거할 경우
- 최소 원소를 제거한 후에 힙에 있는 가장 마지막 원소(밑바닥 가장 왼쪽에 위치한 원소)와 교환합니다.
- 최소 힙의 성질을 만족하도록, 해당 노드를 자식 노드와 교환해 나감으로써 밑으로 내보냅니다.
[ 트라이(접두사 트리) ]
👀 트라이
: n-차 트리(n-ary tree)의 변종으로 각 노드에 문자를 저장하는 자료구조로 '*노드'(널 노드/null node)는 종종 단어의 끝을 나타냅니다. 접두사를 빠르게 찾아보기 위한 아주 흔한 방식입니다.
트라이에서 각 노드는 1개에서 ALPHABET_SIZE + 1개까지 자식을 갖고 있을 수 있습니다. 만약 널 노드 대신 불린 플래그로 표현했다면 0개에서 ALPHABET_SIZE까지입니다.
⭐ 해시 테이블을 이용하면 주어진 문자열이 유효한지 아닌지 빠르게 확인할 수 있지만, 그 문자열이 어떤 유효한 단어의 접두사인지 확인할 수는 없습니다. 하지만 트라이를 이용하면 아주 빠르게 확인할 수 있습니다.
[ 그래프 ]
: 단순히 노드와 그 노드를 연결하는 간선(edge)을 하나로 모아놓은 것과 같습니다.
그래프는 방향성이 있을 수도 있고 없을 수도 있으며 여러 개의 고립된 부분 그래프로 구성될 수도 있고 사이클이 존재할 수도 있고 존재하지 않을 수도 있습니다.
- 일방통행 : 방향성이 있는 간선
- 양방향 통행 : 방향성이 없는 간선
- 연결 그래프 : 모든 정점 쌍 간에 경로가 존재하는 그래프
- 비순환 그래프 : 사이클이 없는 그래프
⭐ 트리는 사이클이 없는 하나의 연결 그래프로 그래프의 한 종류입니다.
👀 인접 리스트
: 그래프를 표현할 때 사용되는 가장 일반적인 방법으로 모든 정점(혹은 노드)을 인접 리스트에 저장합니다.
⭐ 무방향 그래프에서는 (a, b) 간선은 2번 저장됩니다.
class Graph{
public Node[] nodes;
}
class Node{
public String name;
public Node[] children;
}⭐ 그래프는 트리와 달리 특정 노드에서 다른 모든 노드로 접근이 가능하지는 않아 Graph라는 클래스를 사용합니다.
👀 인접 행렬
: NxN 불린 행렬로써 matrix [i][j]가 true라면 i에서 j로의 간선이 있다는 뜻입니다. N은 노드의 개수를 뜻하며 0과 1을 이용한 정수 행렬을 사용할 수도 있습니다. 무방향 그래프를 인접 행렬로 표현하면 대칭 행렬이 됩니다.
⭐ 인접 행렬은 조금 효율성이 떨어집니다. 인접 리스트에서는 어떤 노드에 인접한 노드들을 쉽게 찾을 수 있었지만 인접 행렬에서는 모든 노드를 전부 순회해야 알 수 있습니다.
[ 그래프 탐색 ]
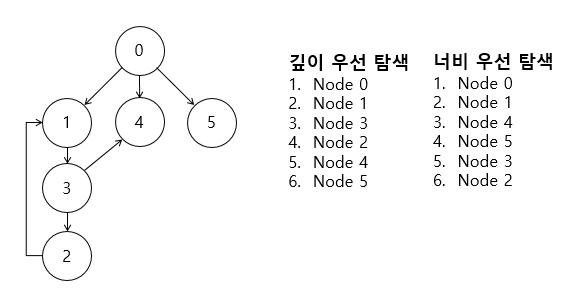
👀 깊이 우선 탐색(Depth-First Search)
: 루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법. 즉, 넓게 탐색하기 전에 깊게 탐색
void search(Node root){
if(root == null) return;
visit(root);
root.visited = true;
for each (Node n in root.adjacent){
if(n.visited == false){
search(n);
}
}
}⭐ 전위 순회를 포함한 다른 형태의 트리 순회는 모두 DFS의 한 종류입니다. 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사해야 합니다.
👀 너비 우선 탐색(Breadth-First Search)
: 루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법. 즉, 깊게 탐색하기 전에 넓게 탐색
void search(Node root){
Queue queue = new Queue();
root.marked = true;
queue.enqueue(root);
while (!queue.isEmpty()){
Node r = queue.dequeue();
visit(r);
foreach (Node n in r.adjacent){
if(n.marked == false){
n.marked = true;
queue.enqueue(n);
}
}
}
}⭐ 너비 우선 탐색 시 que를 사용하며 dequeue는 삭제(remove)와 동일하고 enqueue는 추가(add)와 동일합니다.
👀 양방향 탐색
: 출발지와 도착지 사이에 최단 경로를 찾을 때 사용됩니다. 출발지와 도착지 두 노드에서 동시에 너비 우선 탐색(BFS)을 수행한 뒤, 두 탐색 지점이 충돌하는 경우에 경로를 찾는 방식입니다.
이전 글 참고하기!
2022.12.05 - [프로그램 언어/미분류] - [코딩 인터뷰]자료구조 - 스택과 큐
2022.10.14 - [프로그램 언어/미분류] - [MIT] 파이썬을 이용한 알고리즘의 이해 - 힙 & 힙 정렬
2022.10.19 - [프로그램 언어/미분류] - [MIT] 파이썬을 이용한 알고리즘의 이해 - 일정 예약과 이진 탐색 트리
2022.10.20 - [프로그램 언어/미분류] - [MIT] 파이썬을 이용한 알고리즘의 이해 - 균형 이진 탐색 트리
'프로그램 개발 > 미분류' 카테고리의 다른 글
| [코딩 인터뷰]개념과 알고리즘 - 수학 및 논리 퍼즐 (0) | 2022.12.19 |
|---|---|
| [코딩 인터뷰]개념과 알고리즘 - 비트 조작 (0) | 2022.12.15 |
| [코딩 인터뷰]자료구조 - 스택과 큐 (0) | 2022.12.05 |
| [코딩 인터뷰]자료구조 - 연결리스트 (0) | 2022.12.01 |
| [코딩 인터뷰]자료구조 - 배열과 문자열 (0) | 2022.11.29 |