
저는 미라클 모닝 활동을 하는 것은 아니지만, 매일 아침 경제 유튜버의 커뮤니티 글(경제 내용)을 노션에 정리합니다. 바쁜 아침에 매번 유튜브에 유튜버를 검색해서 정리하다 보니 너무 귀찮았습니다. 그리하여 python Selenium을 사용하여 유튜브 커뮤니티 글을 가져오는 코드를 만들어 보았습니다.
⭐ 코드가 사용된 환경은 jupyter notebook 입니다.
Selenium
Selenium은 웹 테스트 자동화 프레임워크입니다. webdriver를 이용하여 웹 UI나 기능 테스트에 주로 사용합니다. 이러한 특성 때문에 Selenium을 활용하면 웹상의 업무를 자동화할 수도 있습니다.
👀 python으로 사이트의 정보를 추출할 때는 주로 BeautifulSoup 라이브러리를 사용합니다. 하지만 자바스크립트로 생선 된 동적 정보는 가져올 수 없다는 단점이 있습니다. 이러한 단점 때문에 Selenium을 사용하여 데이터를 수집했습니다.
Selenium 설치하기
!pip install selenium
Youtube 커뮤니티 구성 보기
⭐ YouTube Korea 페이지로 예를 들어보았습니다.
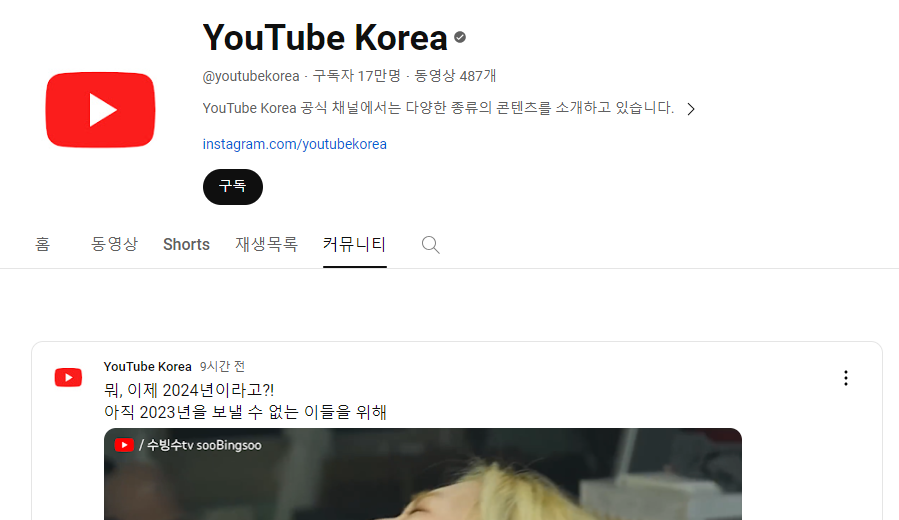
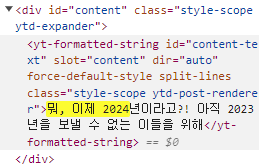
커뮤니티의 구성을 톺아보면 "yt-formatted-string"이라는 커스텀 태그 안에 id로 "content-text"을 사용하고 있습니다. 그리고 기본 창에서는 커뮤니티 글을 총 9개 확인할 수 있습니다. 크롤링할 때 "content-text"를 지표 삼아서 데이터를 가져오면 됩니다. 혹시 커뮤니티 글을 9개 이상 가져오고 싶을 경우 page down을 사용하여 페이지를 내린 다음 데이터를 가져와야 합니다.
코드
# 필요한 라이브러리 import =====================
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# ==============================================
# 브라우저 선택
browser = webdriver.Chrome()
page = "원하는 유튜브 커뮤니티 페이지 주소 입력"
# 사이트 접속하기
browser.get(page)
# 로딩 시간을 위한 1초 시간 지연
time.sleep(1)
# ---------- 페이지를 내려야할 경우 --------------------
# 'body' 부분 찾아서 body 변수에 저장
body = browser.find_element(By.CSS_SELECTOR, 'body')
# 원하는 만큼 for문의 숫자를 변경하시면 됩니다.
for i in range(10):
# 페이지 아래로 내리기
body.send_keys(Keys.PAGE_DOWN)
# 로딩 시간을 위한 3초 시간 지연
time.sleep(3)
# ----------------------------------------------------
# content-text 라는 id를 가진 것들 가져오기
datas = browser.find_elements(By.ID, "content-text")
# 데이터 추출
for data in datas:
print(data.text)
# 1초 시간 지연
time.sleep(1)
# 브라우저 닫기
browser.close()
가장 최근 데이터를 추출할 경우에는 데이터 추출 부분에서 for문 대신 datas[0].text를 바로 print 하시면 됩니다.
'프로그램 개발 > Python' 카테고리의 다른 글
| [python] 금과 달러의 상관관계(FinanceDataReader, Pyplot, Pandas) (2) | 2024.01.18 |
|---|---|
| [python] 이미지 속 한글 추출하기(OpenCV, Pyplot, Pytesseract) (0) | 2024.01.12 |
| [Notion/python] notion-client rich text (0) | 2023.01.26 |
| [python] 미국 국채 금리 확인하기(yfinance) (0) | 2023.01.11 |
| [python] 미국 증시 3대 지수 확인하기(yfinance) (0) | 2023.01.10 |