[ 대부분의 문제에 사용한 Node 클래스 ]
class Node:
def __init__(self, name):
self.name = name
self.left = None
self.right = None
[ 노드 사이의 경로 ]
방향 그래프가 주어졌을 때 두 노드 사이에 경로가 존재하는지 확인하는 알고리즘
이 문제에서 사용할 Node와 Graph▼
state = ("Unvisited", "Visited", "Visiting")
class Node:
def __init__(self, name):
self.name = name
self.state = state[0]
self.adjacent = []
def setAdjacent(self, node):
self.adjacent.append(node)
def getAdjacent(self):
return self.adjacent
class Graph:
def __init__(self, nodes):
self.nodes = nodes
def getNodes(self):
return self.nodesstate = ("Unvisited", "Visited", "Visiting")
def BFS(g: Graph, start: Node, end: Node):
if start == end: return True
# 탐색 전 초기화
q = []
for u in g.getNodes():
u.state = state[0]
# 탐색 시작
start.state = state[2]
q.append(start)
while not q == []:
u = q.pop(0)
if u is not None:
# 인접 노드 탐색
for v in u.getAdjacent():
if v.state == state[0]:
if v is end:
return True
else:
v.state = state[2]
q.insert(0, v)
u.state = state[1]
return False👀 BFS와 DFS로 알고리즘을 작성할 수 있지만 두 노드 사이의 최단 경로를 찾을 때 BFS 형식을 사용하기 때문에 BFS형식으로 코드를 만들었습니다.
[ 최소 트리 ]
오름차순으로 정렬된 배열이 있습니다. 이 배열 안에 들어 있는 원소는 정수이며 중복된 값이 없다고 했을 때 높이가 최소가 되는 이진 탐색 트리를 만드는 알고리즘
def createMinBST(arr):
if not arr: return None
mid = len(arr)//2
n = Node(arr[mid])
n.left = createMinBST(arr[:mid])
n.right = createMinBST(arr[mid+1:])
return n👀 배열의 가운데 원소를 기준으로 왼쪽과 오른쪽으로 나누어서 작은 값은 왼쪽 큰 값은 오른쪽에 설정되도록 재귀 형식으로 코드를 만들었습니다.
[ 깊이의 리스트 ]
이진 트리가 주어졌을 때 같은 깊이에 있는 노드를 연결 리스트로 연결해 주는 알고리즘
이 문제에 사용한 Node는 위의 문제와 같습니다.
⭐ 트리의 깊이가 D라면 D개의 연결리스트를 만들어야 합니다.
def createLevelLinkedList(root, lists, level):
if root is None: return
list = []
if len(lists) == level:
lists.append(list)
else:
list = lists[level]
list.append(root)
createLevelLinkedList(root.left, lists, level+1)
createLevelLinkedList(root.right, lists, level+1)
return lists👀 아무 순회를 응용하여도 상관없지만 전위 순회를 사용하여서 코드를 만들었습니다. 테스트 시 좀 더 직관적으로 확인하고 싶으시면 list.append(root) 대신 list.append(root.name)을 사용하시면 됩니다.
[ 균형 확인 ]
이진트리가 균형 잡혀있는지 확인하는 함수
⭐ 이 문제에서 균형 잡힌 트리는 모든 노드에 대해서 왼쪽 부분 트리의 높이와 오른쪽 부분 트리의 높이의 차이가 최대 하나인 트리를 의미합니다.
def checkHeight(root):
if root is None: return -1
leftH = checkHeight(root.left)
if leftH == float('inf'): return float('inf')
rightH = checkHeight(root.right)
if rightH == float('inf'): return float('inf')
heightDiff = leftH - rightH
if abs(heightDiff)>1:
return float('inf')
else:
return max(leftH, rightH)+1
def isBalanced(root):
return checkHeight(root) != float('inf')👀 왼쪽과 오른쪽을 비교하여 높이 차이가 최대 1이면 True이고 1 초과면 False를 반환하는 코드를 만들었습니다.
[ BST 검증 ]
주어진 이진 트리가 이진 탐색 트리인지 확인하는 함수
def checkBST(n, min=None, max=None):
if n is None: return True
if (min is not None and n.name <= min) or (max is not None and n.name > max):
return False
if (not checkBST(n.left, min, n.name)) or (not checkBST(n.right, n.name, max)):
return False
return True👀 현재 노드가 왼쪽 노드보다 큰지 오른쪽 노드보다 작은 지를 비교하여 True나 False로 반환하는 코드를 만들었습니다.
[ 후속자 ]
이진 탐색 트리에서 주어진 노드의 '다음' 노드(중위 후속자)를 찾는 알고리즘
⭐ 중위 순회 : 왼쪽 하위 → 현재 노드 → 오른쪽 하위
⭐ 중위 후속자 : 중위 순회를 할 때 현재 노드 다음 순회할 노드
def inorderSucc(n):
if n is None: return None
if n.right is not None:
return leftMostChild(n.right)
else:
q = n
x = q.parent
while (x is not None) and (x.left is not q):
q = x
x = x.parent
return x if x is not None else q
def leftMostChild(n):
if n is None: return None
while n.left is not None:
n = n.left
return n👀 중위 순회를 응용하여 코드를 만들었습니다. 오른쪽 자식이 존재하면 오른쪽 부분 트리에서 가장 왼쪽 노드를 반환하고 오른쪽 자식이 존재하지 않을 경우 왼쪽에 있을 때까지 부모 노드로 올라갑니다. 부모 노드가 없을 경우(root 노드) 현재 노드를 반환합니다.
[ 순서 정하기 ]
프로젝트의 리스트와 프로젝트들 간의 종속 관계(즉, 프로젝트 쌍이 리스트로 주어지면 각 프로젝트 쌍에서 두 번째 프로젝트가 첫 번째 프로젝트에 종속되어 있다는 뜻)가 주어졌을 때, 프로젝트를 수행해 나가는 순서를 찾는 알고리즘
⭐ 유효한 순서가 존재하지 않으면 에러를 반환합니다.
예시) 입력 : 프로젝트 : a, b, c, d, e, f 종속관계: (a, d), (f, b), (b, d), (f, a), (d, c)
출력 : f, e, a, b, d, c

def orderProjects(projects, dependencies):
level = {project: 0 for project in projects}
p = {project: [] for project in projects}
starts = set(p for p in projects)
for d in dependencies:
p[d[0]].append(d[1])
starts -= set(d[1])
for s in starts:
cnt = 1
tmp = set(p[s])
tmp2 = set()
while tmp:
t = tmp.pop()
level[t] = max(level[t], cnt)
tmp2.add(t)
if not tmp:
cnt += 1
for i in tmp2:
tmp |= set(p[i])
tmp2 = set()
level = sorted(level.items(), key=lambda x: x[1])
return ', '.join([k for k, v in level])👀 종속이 한 방향으로 흘러간다고 가정하고(가령 예시의 값 중 f가 c에 종속된다는 것이 없는 것) 출력 시 굳이 노드 형태로 출력을 하지 않아도 된다면 위와 같이 쉽게 코드를 만들 수도 있습니다.
[ 첫 번째 공통 조상 ]
이진트리에서 노드 두 개가 주어졌을 때 이 두 노드의 첫번째 공통 조상을 찾는 알고리즘
⭐ 자료구조 내에 추가로 노드를 저장해 두면 안되고 반드시 이진 탐색 트리일 필요는 없습니다.
class Result:
def __init__(self, node, isAncestor):
self.node = node
self.isAncestor = isAncestor
def commonAncestor(root, p, q):
r = AncHelper(root, p, q)
if r.isAncestor: return r.node
return None
def AncHelper(root, p, q):
if root is None: return None
if root == p and root == q:
return Result(root, True)
rx = AncHelper(root.left, p, q)
if rx.isAncestor:
return rx
ry = AncHelper(root.right, p, q)
if ry.isAncestor:
return ry
if rx.node is not None and ry.node is not None:
return Result(root, True)
elif root == p or root == q:
tmp = (rx.node is not None) or (ry.node is not None)
return Result(root, tmp)
else:
return Result(rx.node if rx.node is not None else ry.node, False)👀 Result라는 class를 제작하여 노드와 부모가 존재하는지 여부를 저장하고 AncHelper라는 함수를 제작하여 재귀적으로 문제를 풀도록 코드를 만들었습니다. root와 비교할 2가지 노드를 입력으로 받아서 root에서 내려가면서 비교합니다.
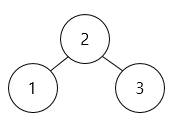
[ BST 수열 ]
배열의 원소를 왼쪽에서부터 차례로 트리에 삽입함으로써 이진 탐색 트리를 생성할 때 해당 트리를 만들어 낼 수 있는 가능한 배열을 모두 출력하는 알고리즘
⭐ 이진 탐색 트리 안에서 원소가 중복되지 않습니다.
예시) node(2) → node(1), node(3) ⇒ [[2, 1, 3], [2, 3, 1]]
def allSequences(node):
result = []
if node is None:
result.append([])
return result
prefix = [node.name]
# 왼쪽과 오른쪽 부분 트리 재귀
leftSeq = allSequences(node.left)
rightSeq = allSequences(node.right)
# 왼쪽과 오른쪽 합치기
for left in leftSeq:
for right in rightSeq:
weaved = weaveLists(left, right, [], prefix)
result += weaved
return result
# 모든 가능한 방법으로 합치기
def weaveLists(first, second, results, prefix):
if len(first) == 0 or len(second) == 0:
result = prefix.copy()
result += first
result += second
results.append(result)
return results
for i in [first, second]:
tmp = i.pop(0)
prefix.append(tmp)
results = weaveLists(first, second, results, prefix)
prefix.pop()
i.insert(0, tmp)
return results
[ 하위 트리 확인 ]
두 개의 커다란 이진 트리 T1과 T2가 있을 때 T2가 T1의 하위 트리인지 판별하는 알고리즘
⭐ T1 안에 있는 노드 n의 하위 트리가 T2와 동일하면, T2는 T1의 하위 트리입니다. 즉, T1에서 노트 n의 아래쪽을 끊어 냈을 때 그 결과가 T2와 동일해야 합니다.
def containsTree(t1, t2):
# 비어있는 트리는 언제나 하위 트리입니다.
if t2 is None: return True
return subTree(t1, t2)
def subTree(r1, r2):
# 큰 트리는 비어 있을 경우
if r1 is None: return False
elif r1.name == r2.name and matchTree(r1, r2):
return True
return subTree(r1.left, r2) or subTree(r1.right, r2)
def matchTree(r1, r2):
if r1 is None and r2 is None: # 둘다 하위 트리가 없다
return True
elif r1 is None or r2 is None: # 트리가 한쪽이 비어있을 경우
return False
elif r1.name != r2.name: # 값이 다르다
return False
else: # 계속해서 탐색
return matchTree(r1.left, r2.left) and matchTree(r1.right, r2.right)👀 2개의 트리 중 더 큰 트리(T1)를 탐색하면서 T2의 루트와 같은 노드를 발견할 때마다 matchTree를 이용하여 동일한지 검사합니다.
[ 임의의 노드 ]
노드의 삽입, 검색, 삭제뿐만 아니라 임의의 노드를 반환하는 getRandomNdoe() 메서드도 구현
⭐ getRandomNode() : 모든 노드를 같은 확률로 선택
import random
class TreeNode:
def __init__(self, name):
self.name = name
self.left = None
self.right = None
self.size = 1
def getRandomNode(self):
if self is None: return None
idx = random.randrange(0, self.size)
return self.getIthNode(idx)
def getIthNode(self, idx):
leftSize = self.left.size if self.left else 0
if idx < leftSize:
return self.left.getIthNode(idx)
elif idx == leftSize:
return self
else:
return self.right.getIthNode(idx - (leftSize+1))
def insertInOrder(self, d):
if d <= self.name:
if self.left is None:
self.left = TreeNode(d)
else:
self.left.insertInOrder(d)
else:
if self.right is None:
self.right = TreeNode(d)
else:
self.right.insertInOrder(d)
self.size += 1
def find(self, d):
if d == self.name:
return self
elif d <= self.name:
return self.left.find(d) if self.left is not None else None
elif d > self.name:
return self.right.find(d) if self.right is not None else None
else:
return None👀 삭제의 경우 find로 찾은 노드를 None으로 설정해주면 되지 않을까 생각합니다.
[ 합의 경로 ]
각 노드의 값이 정수(음수 및 양수)인 이진트리가 있을 때 정수의 합이 특정 값이 되도록 하는 경로의 개수를 세는 알고리즘
⭐ 경로가 꼭 루트에서 시작해서 말단 노드에서 끝날 필요는 없지만 반드시 아래로 내려가야 합니다. 즉, 부모 노드에서 자식 노드로만 움직일 수 있습니다.
예시)

def countPathsWithSum(node, targetSum, nowSum = 0, memo = {}):
if node is None: return 0
# 현재 노드에서 끝나면서 합의 조건을 만족하는 경로의 개수
nowSum += node.name
s = nowSum - targetSum
totalPaths = memo.get(s, 0)
# nowSUm과 targetSUm이 같다면 루트에서 시작하는 경로가 추가로 더 존재한다는 의미
if nowSum == targetSum:
# 이 경로 1개 추가
totalPaths += 1
# memo를 증가시키고 재귀호출 뒤 다시 감소
memo = MeMo(memo, nowSum, 1)
for i in [node.left, node.right]:
totalPaths += countPathsWithSum(i, targetSum, nowSum, memo)
memo = MeMo(memo, nowSum, -1)
return totalPaths
def MeMo(dic, key, delta):
newCnt = dic.get(key, 0) + delta
if newCnt == 0:
del dic[key]
else:
dic.setdefault(key, newCnt)
dic[key] = newCnt
return dic'프로그램 개발 > Python' 카테고리의 다른 글
| [코딩 인터뷰]개념과 알고리즘 - 객체 지향 설계 문제(카드 한 벌:Python) (0) | 2022.12.22 |
|---|---|
| [코딩 인터뷰]개념과 알고리즘 - 비트 조작 문제(Python) (1) | 2022.12.18 |
| [코딩 인터뷰]자료구조 - 스택과 큐 문제(Python) (0) | 2022.12.06 |
| [코딩 인터뷰]자료구조 - 연결리스트 문제(Python) (1) | 2022.12.02 |
| [코딩 인터뷰]자료구조 - 배열과 문자열 문제(Python) (1) | 2022.11.30 |