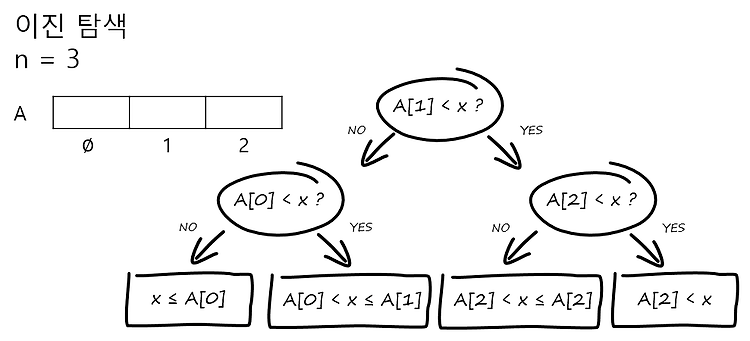
BoostCourse의 "[MIT]파이썬을 이용한 알고리즘의 이해" 강의 내용을 정리한 글입니다. ✔ 그래프 탐색 그래프 탐색은 "그래프를 탐험하다"는 것이라고 할 수 있습니다. 그래프를 탐색하는데 여러 가지 개념들이 있습니다. 시작 점 s에서 원하는 정점으로의 경로를 찾는 것 그래프의 또는 s에서 도달할 수 있는 모든 정점과 간선을 방문하는 것 ⁉️ 그래프 : G = (V, E) V = 정점의 집합(임의의 레이블) E = 간선의 집합, 정점의 쌍(v, w) - 순서쌍 ⇒ 그래프의 방향이 있는 간선 - 비순서쌍 ⇒ 무방향 ⁉️ 응용 웹크롤링(구글이 페이지를 찾는 방법) 소셜 네트워킹(페이스북이 친구 찾기를 사용하는 법) 네트워크 브로드캐스트 라우팅 가비지 컬렉션 모델 검사(무한 상태 기계) 수학적 추측 ..